AI-powered Teaching Assistant
When you use an AI recipe, Teaching Assistant will help you improve and modify your padlet board.


About
What is it?
Teaching Assistant is an AI-powered feature that teachers can access while viewing an AI recipe they've created in Padlet. It allows users to chat with the assistant and request a wide variety of updates to their padlet.
Why is it interesting?
It uses the current best model in the world for this type of task (gpt-4o-2024-08-06) to create a chat experience that our users will find incredibly smooth and easy to use
Who is it for?
Teaching Assistant is currently restricted to Teachers, Admins, and Owners within School Libraries, Padlet for Schools, or Classroom accounts.
Where can I access it?
- Create a board using any AI recipes (other than Discussion Board)
- When the board loads, the assistant panel will automatically open and suggest further improvements to the board.
When is it available?
Now!
What’s next?
- We're working on improving reliability, as sometimes the assistant acts unpredictably.
- We plan to eventually release this feature to a broader selection of user accounts.
Technical details
Underlying tech
Our Teaching Assistant is an AI agent, making decisions about the actions it should take based on the context of the situation. AI agents represent the cutting edge of AI capabilities, and we are working at the limit of what frontier Large Language Models (LLMs) are capable of.
After each user message, the agent can decide to either:
- Respond with a message
- Call a function to update the padlet
- Search a PDF of Padlet's knowledge base to find information about features
There's a significant amount of underlying logic and technology besides the LLM that needs to come together to enable an assistant like this, including:
- Logic to orchestrate the agent loop
- Retrieval-Augmented Generation (RAG) for file search
- Managing thread history with a database
- Managing the context window when invoking the LLM
- Streaming the responses
- Validating function calls and turning them into Padlet updates
Given our tight deadline and limited resources (two dedicated engineers), we had two viable options: Langchain or OpenAI's Assistants API. We chose the Assistants API because it offered everything we needed for the v1 version and was easier to set up.
We created a new Python API service called Morpheus to use the OpenAI SDK to manage the assistant. We chose FastAPI as the architecture for this service due to its built-in concurrency and wide deployment in production environments.
Here is a high-level diagram of the system we built, showing the flow of a user sending a message that results in a function call. This is after the assistant and message thread have been initialized.
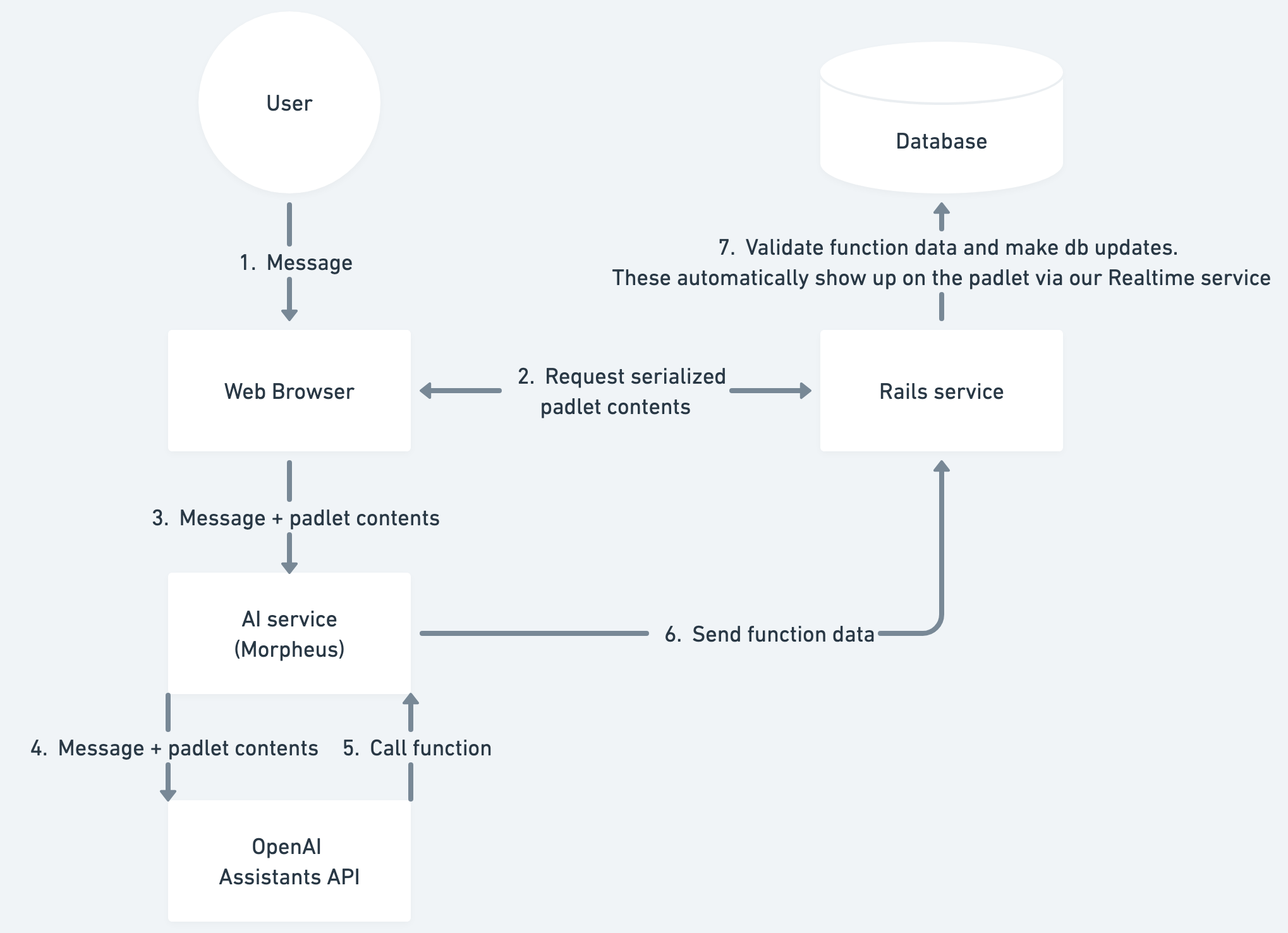
Integrated test system
We quickly built a prototype, and the initial results were promising. It was still an open question whether the agent could reliably make useful updates to a padlet based on user requests.
One of the biggest challenges of working with LLMs is testing that changes you make to the prompt are actually an improvement. Changing the prompt can have unpredictable effects, and LLMs are not deterministic unless you set the “temperature” of the model to 0, which is generally avoided. In the course of development, we iterated on the prompt around 100 times to get to the current functionality.
Luckily for this feature, there is a way to automatically evaluate a quantitative aspect of the assistant's actions when it makes a function call, which is the most important part of the assistant’s abilities. We can give a clear instruction like “Make 3 posts about Nudibranchs,” run the logic to make the changes based on the function call, and then check at the end whether 3 posts were made on the padlet.
We built a system around this idea, which lets us evaluate the instruction following ability of a given assistant. This test system is more complicated than the Teaching Assistant feature itself and is probably the most complicated system within Padlet.
Because we are using a temperature above 0, we need to run all tests multiple times to get a number that accurately reflects the ability of the assistant. Each test run involves sending ~100 messages to the assistant.
Here is the definition of one of the tests:
class AnimeTest < BaseIntegrationTest
MESSAGES = [
"add a section for another popular anime of your choice. Also add 2 posts to each section that are a character in the anime. Only write in the title of the post, not the body.",
]
def setup_padlet
@padlet = random_padlet
enable_sections!(padlet) unless padlet.grouped_by_section?
padlet.sections.first.update!(title: "Attack on Titan")
random_padlet_section(padlet:, title: "One Punch Man")
end
def evaluate_result
assert_equal true, padlet.grouped_by_section?, "Expected padlet to be grouped by section"
assert_equal 3, padlet.sections.count, "Expected 3 sections, got #{padlet.sections.count}"
assert_equal 6, padlet.posts.count, "Expected 6 posts, got #{padlet.posts.count}"
padlet.sections.each do |section|
assert_equal 2, section.posts.count, "Expected 2 posts in each section, got #{section.posts.count}"
end
padlet.posts.each do |post|
assert_equal true, post.body.blank?, "Expected body to be blank, but body was: #{post.body}"
end
end
end
This inherits from BaseIntegrationTest, which contains the logic when a test is run to:
- Run
setup_wall - Send the next message in
MESSAGESto Morpheus - Wait for a redis cache update that the Rails server makes after receiving the resulting function call and making updates
- Repeat steps 2 and 3 if there are more messages
- Run
evaluate_result
Then we also have an IntegrationTestRunner class. We trigger a test run in a Rails console with IntegrationTestRunner.run_all_tests(["assistant_id1"], repetitions: 10) and the runner:
- Creates 80 concurrent threads
- Orchestrates the threads to collectively run each test
repetitionstimes for each assistant - Prints out the results
An example output:
---- Assistant: asst_abc, Repetitions: 10 --
Total pass rate: 96.0%
Average time of each test: 41 seconds
Total time taken: 93 seconds
This test system was crucial in maximizing the number of iterations we could perform within our time constraints while ensuring we were moving in the right direction. It enabled us to create a reliable and capable assistant.
In conclusion, Padlet's Teaching Assistant represents a significant step forward in AI-assisted education tools. By leveraging cutting-edge AI technology and robust testing methodologies, we've created a feature that we believe will greatly enhance the Padlet experience for educators. We look forward to continued improvements and broader implementation of this technology in the future.